常识内容
本文将讲述计算机常识内容,常识学习有利于计算机语言的理解。
数据存储单位
内存是随机存储器,是无数个元器件形成的电路,只能表示二进制。单个元器件为1bit(比特)
8 bit = 1 Byte 一字节
1024 B = 1 KB (KiloByte) 千字节
1024 KB = 1 MB (MegaByte) 兆字节
1024 MB = 1 GB (GigaByte) 吉字节
1024 GB = 1 TB (TeraByte) 太字节
1024 TB = 1 PB (PetaByte) 拍字节
1024 PB = 1 EB (ExaByte) 艾字节
1024 EB = 1 ZB (ZetaByte) 泽字节
1024 ZB = 1 YB (YottaByte) 尧字节
1024 YB = 1BB (Brontobyte)珀字节
1024 BB = 1 NB (NonaByte) 诺字节
1024 NB = 1 DB (DoggaByte)刀字节
载入内存运行程序
通过加载器(Loader)将硬盘上保存的程序文件复制到内存中,让CPU执行。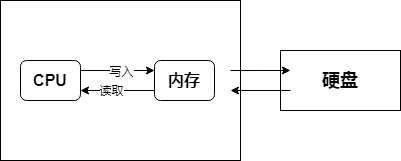
字符编码
字符为了达到通用性和规范性在计算机领域中发展出了字符集和字符编码。
最早专门为英文表达的字符集——ASCII编码 是基于拉丁字母的电脑编码,用于显示现代英语和其他西欧语言,即 (美国信息交换标准代码) 由美国国家标准学会制定。ASCII(American Standard Code for Information Interchange)已成为计算机通用标准。
常见字符编码(由ASCII编码主导,其他通用编码由此扩展而来,以保持兼容)
| 编码方案 | 简介 |
|---|---|
| ISO/IEC 8859 | 欧洲字符集,支持丹麦语、荷兰语、德语、意大利语、拉丁语、挪威语、葡萄牙语、西班牙语、瑞典语 等(1987年首次发布),其主要在ASCII基础上衍生拉丁字母以支持欧洲多国所用的扩展拉丁字母 |
| Shift_Jis | 日语字符集,包含全角及半角拉丁字母,平假名、片假名、符号及日语汉字,1978年首发 |
| Big5 | 繁体中文字符集,1984年发布,通行于台湾、香港等地区,收录了13053个中文汉字、408个普通字符、及33个控制字符 |
| GB2312 | 简体中文字符集,1980年发布,共收录6763个汉字,其中一级汉字3755个,二级汉字3008个,同时收录了包括拉丁字母、希腊字母、日文平假名及片假名,俄语西里尔字母在内的682个字符 |
| GBK | 中文字符集,是在GB2312的基础上进行的扩展,1995年发布。GB2312收录了大陆99.75%使用频率的汉字,但有些人名及古汉语中的罕用字并不能处理,所以将GB2312进行扩展即GBK,GBK共收录了21886个汉字和图形符号,包括GB2312中全部汉字、非汉字符号、及GBK中全部繁体字及生僻字 |
| GB18030 | 中文字符集,对GBK和GB2312又一次扩展,2000年发布。共收录了70244个汉字,支持国内少数民族的文字,及日语韩语中的汉字 |
| UTF-8 | 变长编码方案,使用1~6个字节存储(一个字节最高为0,多字节时按首字节最高位的1的个数判断占几个字节) |
| UTF-32 | 一种固定长度编码方案,使用4个字节存储 |
| UTF-16 | 变长且固定的编码方案,使用2或4个字节存储(0~FFF内按两个字节存储,10000~10FFFF按四个字节存储) |
版权声明

Scholar’s Blog by scholargeek is licensed under a Creative Commons BY-NC-ND 4.0 International License.
由董仕麟创作并维护的scholargeek博客采用创作共用保留署名-非商业-禁止演绎4.0国际许可证。
本文首发于Scholar’s Blog博客,版权所有,侵权必究。
本文永久链接:https://scholargeek.github.io/2018/02/02/C%E8%AF%AD%E8%A8%80%E5%AD%A6%E4%B9%A00/